VB2013で作成した、郵便番号データを住所録データとして使用する為の処理のスクリプトです。
詳しい説明は省略していますし、変数の一部をPUBLICとして設定しているので、このまま使っても動きません。
MDB形式のデータベースを作成し、VB.NETのスクリプトでデータを加工しています。
アルゴリズムや、スクリプトの中身など拙いものですが、参考にして頂ける部分もあるかと思い公開しました。
同じような処理が延々と続きますので、どんなデータを加工しようとしているのか、なるべく明確にしながら記載しました。
新たな問題点や、対処法の検討、対処も行いますので、少しずつですが、変更点は修正していきます。
。
もし、どうしても動かしたい方、内容に疑問のある方は、ブログにコメントを頂ければ幸いです。
ACCESS VBAから移植の為、Dcountなど、関数を作っている部分もあります。
デバッグでの動作は確認していますが、ビルドしての動作は未確認です。
*ZIPファイルの解凍にライブラリを使用していますので、.NET Framework 4.5以上が必要です。
*リンクフリーです。
*著作権も放棄します。
*記載内容の不備、改良のご指摘は大歓迎です。サイクルメンテあのこら 南(tom@anocora.com)までご連絡下さい。
*この記載によって、何らかの障害、損害が生じても、一切の責任は取りません。自己責任でご使用ください。
*まだ未完成です。取り敢えず、スペースでの町域データ分離までは自信が持てるようになったので公開しました。
今後、順次公開します。
ここで作成しようとしている住所入力は、出張修理の為の、ご訪問先の入力です。
ご依頼をお受けする場合、ご住所の問いかけに対し、郵便番号からお答えいただくことは稀なケースになります。
ほとんどの方が、○○市□□町△△の××とお答えになりますので、電話で受け答えしながら、住所入力を完了したいのです。
受話器を持っているため、片手しか空いていません。
なるべく、簡単に入力するため、コンボでのデータ選択を基本の入力とします。
コンボの選択肢がすぐ見つけられるように10件前後の選択肢にしたいです。
その為に、都道府県、市町村、(区)、町域、補足になるべくデータを細分化します。
下記の処理の相当部分を処理されたデータを公開さ入れているサイトも有り、データはこちらからダウンロードできますが、市と区の分離、郡データの削除等、追加が必要なこともあり、全て自分で加工しました。
| 手順 | 処理 | CSVファイル |
| 1 | 分割された町域データのマージ | Merge_Zip.CSV |
| 2 | 町域に「以下に掲載がない場合」と記載されたレコード削除 | Merge_Zip_1.CSV |
| 3 | (次のビルを除く)と「・階層不明」の文言の削除 | Merge_Zip_2.CSV |
| 4 | 「市区町村一円」の文言の削除 | Merge_Zip_3.CSV |
| 町域補足項目への移動 | ||
| 政令市の市と区の分離 | ||
| 住所入力に不要な郡表記の削除 | ||
| 「市区町村の次に番地がくる場合」の文言の(その他)への変更 | ||
郵便番号データを住所入力で使おうとすると、いくつか課題が有ります。
郵便番号データは、住所に読み仮名データが付付与されており、カナ表記のカナ版とローマ字表記のローマ字版が有ります。
(カナ版は、促音・拗音を小書きで表示したものと小書きになっていないものがあります。)
カナ版は、市区、郡町村が分割されていませんが、ローマ字版では、○○市 □□区、○○郡 □□町のようにスペースで分割されていますので、ローマ字版を使うと、細分化が行いやすいです。
ローマ字版ですべてが対応できればいいのですが、多少課題が有ります。
・ローマ字版では、町域のデータが17文字でカットされて居て、マージをしても正しいデータになりません。
・ローマ字の表記がヘボン式の為、カナ入力でキーボードを打つ時と差異が出ます。
・ローマ字版と、カナ版では郵便番号データのレコード件数が異なります。
・住所データがスペースで区切られていても、読み仮名がスペースで区切られていないレコードが有ります。
・住所データがスペースで区切られていなくても、読み仮名がスペースで区切られているレコードが有ります。
*カナ版とローマ字版では、データ件数も異なり、カナ版の方が正確なデータのようですので、ローマ字版は使いません。
郵便番号データは、ヘッダー情報を持っていないので、項目名は適当に決めています。
anocora.mdbというデータベースを使っています。
スクリプト内のDB名をを適宜変更すれば、他のACCESS(jet) DBで動きます。
処理するうえで、必須なテーブルがいくつかありますので、別途mdbデータとして、公開します。
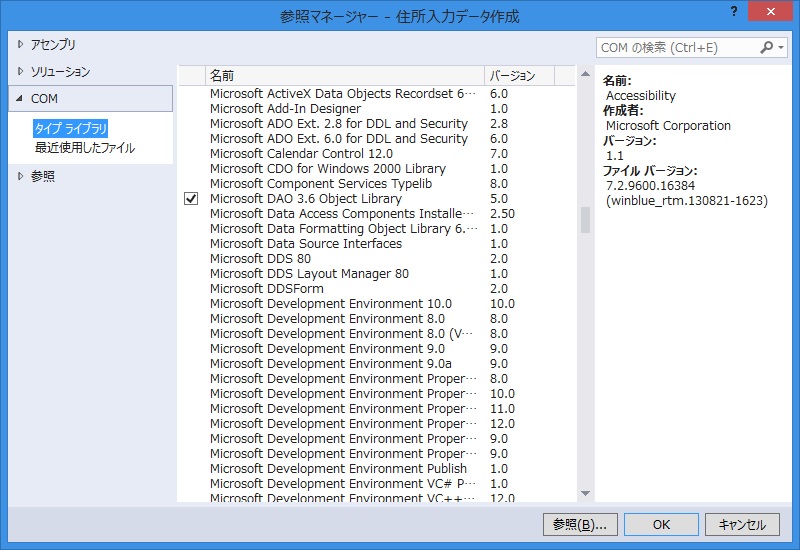
Access.DBを使っていることと、個人的な馴染みの問題で、DAOによるアクセスを使っています。
上記の参照設定が必要です。
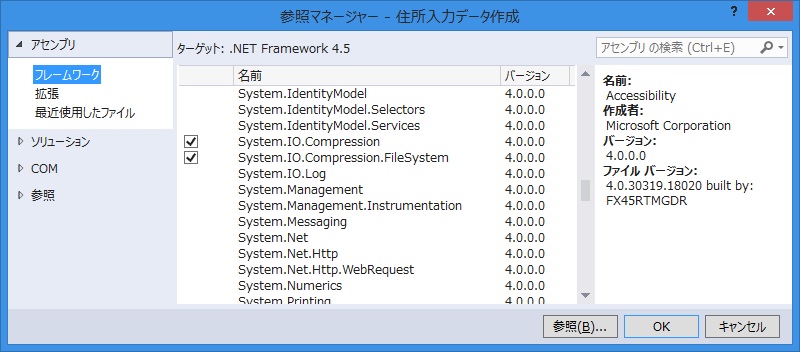
下記の宣言に記載した
Imports System.IO
Imports System.IO.Compression
が必須です
こんなフォームを使っています。
見た目の問題で、一部配置を変えました。
フォームの詳細は、こちらに置きます。
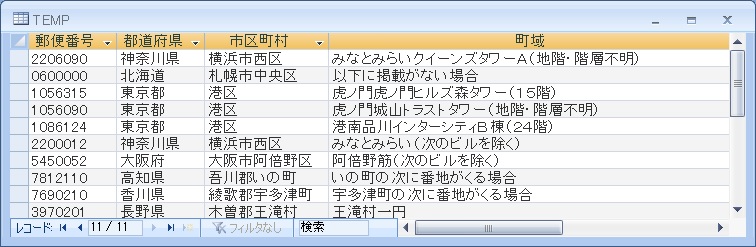

町域がスペースで区切られたデータ

括弧の前に付いたスペースの除去
読み仮名がスペースで区切られていないデータ。
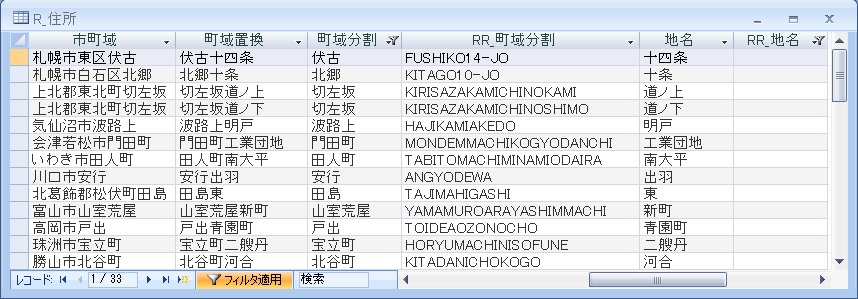
読み仮名のみスペースで区切られたデータ
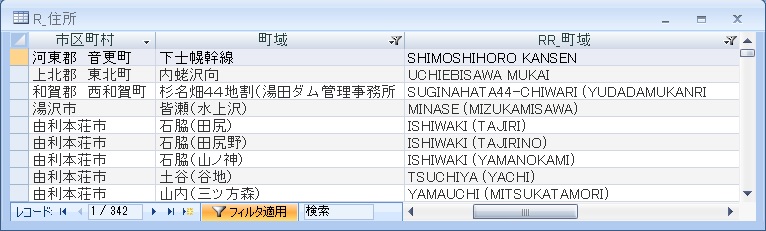
スペースで重複して区切られたデータ
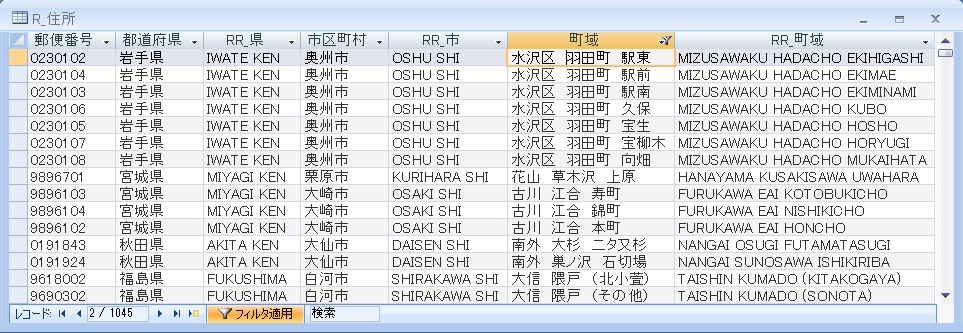

町域に残った括弧内のデータ
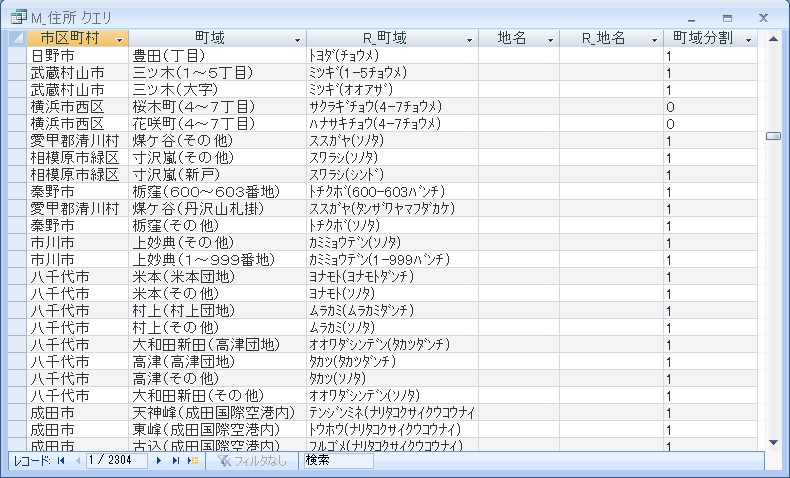
(その他),(丁目),(番地),(番地のみ),(大字),(大字、番地),(無番地),(無番地を除く),(全域)または(各町)の記載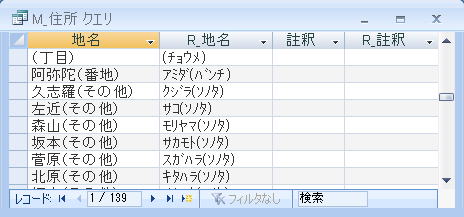
地名に続く括弧内データ
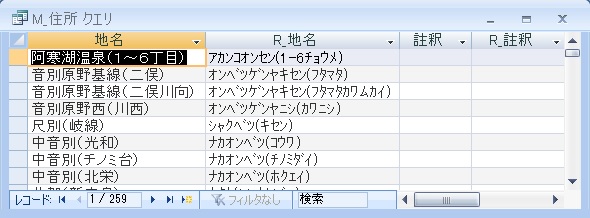
丁目、番地以外の文字列を含まない()内のデータ
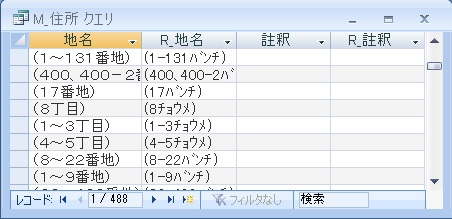
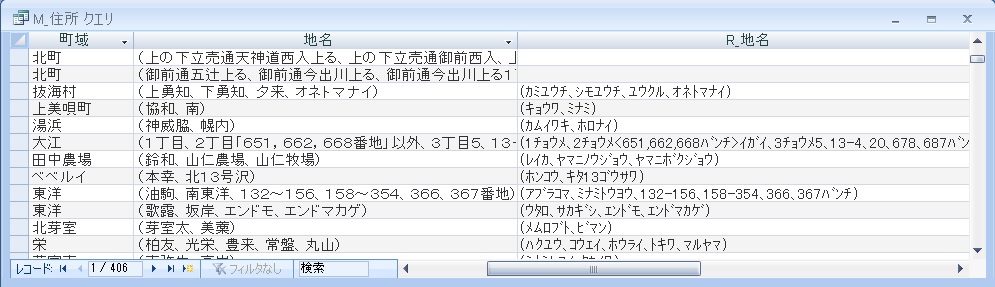
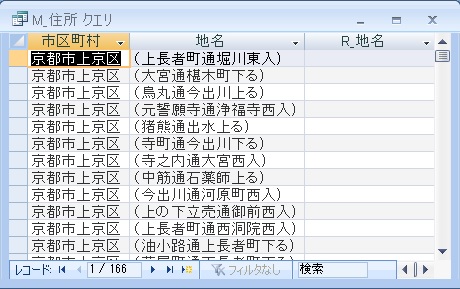
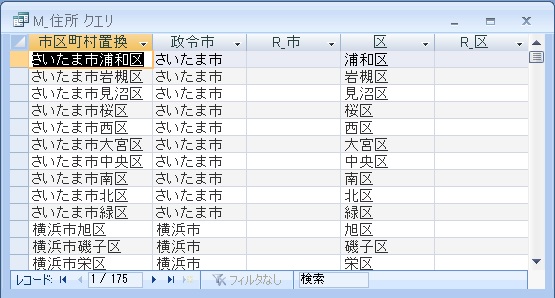
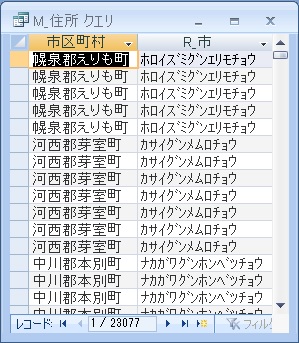
ここまでは、多少は汎用性があると思います。
ここから先は、業務システム用の専用処理です。